
Subdomain enumeration is a fundamental and very important part of any offensive reconnaissance, discovering points of entry, exposed assets and/or information that will aid in further compromise of the target’s infrastructure.
Until recently, I’ve had a small go-to collection of wordlists for this process that I will use, admittedly, without much thought as to how they were compiled and assembled in the first place, so I decided to try and make my own.
SSL Certificate Data 🪪
SSL certificates contain a list of domains for which the specific certificate is valid, allowing one certificate to be used across multiple services. This includes subdomains and wildcards as well.
For example, running nmap with the ssl-cert script, we can see that google.com serves an SSL cert on HTTP port 443/tcp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ nmap -p 443 --script ssl-cert google.com ─╯
Starting Nmap 7.93 ( https://nmap.org )
Nmap scan report for google.com (142.250.179.78)
Host is up (0.054s latency).
rDNS record for 142.250.179.78: par21s19-in-f14.1e100.net
PORT STATE SERVICE
443/tcp open https
| ssl-cert: Subject: commonName=*.google.com
| Subject Alternative Name: DNS:*.google.com, DNS:*.appengine.google.com, DNS:*.bdn.dev, DNS:*.origin-test.bdn.dev, DNS:*.cloud.google.com, DNS:*.crowdsource.google.com, DNS:*.datacompute.google.com, DNS:*.google.ca, DNS:*.google.cl, DNS:*.google.co.in, DNS:*.google.co.jp, DNS:*.google.co.uk, DNS:*.google.com.ar, DNS:*.google.com.au, DNS:*.google.com.br, DNS:*.google.com.co, DNS:*.google.com.mx, DNS:*.google.com.tr, DNS:*.google.com.vn, DNS:*.google.de, DNS:*.google.es, DNS:*.google.fr, DNS:*.google.hu, DNS:*.google.it, DNS:*.google.nl, DNS:*.google.pl, DNS:*.google.pt, DNS:*.googleadapis.com, DNS:*.googleapis.cn, DNS:*.googlevideo.com, DNS:*.gstatic.cn, DNS:*.gstatic-cn.com, DNS:googlecnapps.cn, DNS:*.googlecnapps.cn, DNS:googleapps-cn.com, DNS:*.googleapps-cn.com, DNS:gkecnapps.cn, DNS:*.gkecnapps.cn, DNS:googledownloads.cn, DNS:*.googledownloads.cn, DNS:recaptcha.net.cn, DNS:*.recaptcha.net.cn, DNS:recaptcha-cn.net, DNS:*.recaptcha-cn.net, DNS:widevine.cn, DNS:*.widevine.cn, DNS:ampproject.org.cn, DNS:*.ampproject.org.cn, DNS:ampproject.net.cn, DNS:*.ampproject.net.cn, DNS:google-analytics-cn.com, DNS:*.google-analytics-cn.com, DNS:googleadservices-cn.com, DNS:*.googleadservices-cn.com, DNS:googlevads-cn.com, DNS:*.googlevads-cn.com, DNS:googleapis-cn.com, DNS:*.googleapis-cn.com, DNS:googleoptimize-cn.com, DNS:*.googleoptimize-cn.com, DNS:doubleclick-cn.net, DNS:*.doubleclick-cn.net, DNS:*.fls.doubleclick-cn.net, DNS:*.g.doubleclick-cn.net, DNS:doubleclick.cn, DNS:*.doubleclick.cn, DNS:*.fls.doubleclick.cn, DNS:*.g.doubleclick.cn, DNS:dartsearch-cn.net, DNS:*.dartsearch-cn.net, DNS:googletraveladservices-cn.com, DNS:*.googletraveladservices-cn.com, DNS:googletagservices-cn.com, DNS:*.googletagservices-cn.com, DNS:googletagmanager-cn.com, DNS:*.googletagmanager-cn.com, DNS:googlesyndication-cn.com, DNS:*.googlesyndication-cn.com, DNS:*.safeframe.googlesyndication-cn.com, DNS:app-measurement-cn.com, DNS:*.app-measurement-cn.com, DNS:gvt1-cn.com, DNS:*.gvt1-cn.com, DNS:gvt2-cn.com, DNS:*.gvt2-cn.com, DNS:2mdn-cn.net, DNS:*.2mdn-cn.net, DNS:googleflights-cn.net, DNS:*.googleflights-cn.net, DNS:admob-cn.com, DNS:*.admob-cn.com, DNS:googlesandbox-cn.com, DNS:*.googlesandbox-cn.com, DNS:*.gstatic.com, DNS:*.metric.gstatic.com, DNS:*.gvt1.com, DNS:*.gcpcdn.gvt1.com, DNS:*.gvt2.com, DNS:*.gcp.gvt2.com, DNS:*.url.google.com, DNS:*.youtube-nocookie.com, DNS:*.ytimg.com, DNS:android.com, DNS:*.android.com, DNS:*.flash.android.com, DNS:g.cn, DNS:*.g.cn, DNS:g.co, DNS:*.g.co, DNS:goo.gl, DNS:www.goo.gl, DNS:google-analytics.com, DNS:*.google-analytics.com, DNS:google.com, DNS:googlecommerce.com, DNS:*.googlecommerce.com, DNS:ggpht.cn, DNS:*.ggpht.cn, DNS:urchin.com, DNS:*.urchin.com, DNS:youtu.be, DNS:youtube.com, DNS:*.youtube.com, DNS:youtubeeducation.com, DNS:*.youtubeeducation.com, DNS:youtubekids.com, DNS:*.youtubekids.com, DNS:yt.be, DNS:*.yt.be, DNS:android.clients.google.com, DNS:developer.android.google.cn, DNS:developers.android.google.cn, DNS:source.android.google.cn
| Issuer: commonName=GTS CA 1C3/organizationName=Google Trust Services LLC/countryName=US
| Public Key type: ec
| Public Key bits: 256
| Signature Algorithm: sha256WithRSAEncryption
| Not valid before: 2022-12-12T08:16:21
| Not valid after: 2023-03-06T08:16:20
| MD5: b7bc4ae293e806922e01598953e20be8
|_SHA-1: a189b23f2b2353029599ab684d367bd087ed323d
Nmap done: 1 IP address (1 host up) scanned in 0.70 seconds
From the output we can tell that the certificate for google.com is also valid for a whole bunch of other domains and subdomains, for example android.clients.google.com , *.appengine.google.com and so on.
HTTPS isn’t the only protocol using SSL certs though. FTP, SMTP, IMAPS, POP3, XMPP. etc., can too. Here we are looking at the nmap output from scanning the certificate of the IMAPS service on port 993/tcp, belonging to Microsoft Office365:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
$ nmap --script ssl-cert outlook.office365.com -p 993 ─╯
Starting Nmap 7.93 ( https://nmap.org )
Nmap scan report for outlook.office365.com (52.97.201.50)
Host is up (0.053s latency).
Other addresses for outlook.office365.com (not scanned): 52.97.233.2 40.101.138.18 52.97.233.34
PORT STATE SERVICE
993/tcp open imaps
| ssl-cert: Subject: commonName=outlook.com/organizationName=Microsoft Corporation/stateOrProvinceName=Washington/countryName=US
| Subject Alternative Name: DNS:*.clo.footprintdns.com, DNS:*.hotmail.com, DNS:*.internal.outlook.com, DNS:*.live.com, DNS:*.nrb.footprintdns.com, DNS:*.office.com, DNS:*.office365.com, DNS:*.outlook.com, DNS:*.outlook.office365.com, DNS:attachment.outlook.live.net, DNS:attachment.outlook.office.net, DNS:attachment.outlook.officeppe.net, DNS:attachments.office.net, DNS:attachments-sdf.office.net, DNS:ccs.login.microsoftonline.com, DNS:ccs-sdf.login.microsoftonline.com, DNS:hotmail.com, DNS:mail.services.live.com, DNS:office365.com, DNS:outlook.com, DNS:outlook.office.com, DNS:substrate.office.com, DNS:substrate-sdf.office.com
| Issuer: commonName=DigiCert Cloud Services CA-1/organizationName=DigiCert Inc/countryName=US
| Public Key type: rsa
| Public Key bits: 2048
| Signature Algorithm: sha256WithRSAEncryption
| Not valid before: 2022-07-26T00:00:00
| Not valid after: 2023-07-25T23:59:59
| MD5: 990cfeef9a6e727f2312d3e4103726ce
|_SHA-1: f7da87b0b58b2a2eec386ec7a60ab14d5a60a499
So, in theory, if we could harvest the data from every discoverable SSL certificate, we would compile a pretty comprehensive list of actual subdomains used ‘in the wild’.
Scanning Everything 🤷
Let’s scan the entire internet, why don’t we…
I spun up an Amazon Elastic Compute Cloud (EC2) instance and installed masscan, which, if you’ve been living under a rock, is an amazing piece of software designed to scan large ranges of IP addresses at absolutely ridiculous speeds.
Before running masscan we need to firewall the source port that it uses. This prevents the local TCP/IP stack from seeing the packet, but masscan still sees it since it bypasses the local stack. This significantly increases the speed of the scan.
1
$ sudo iptables -A INPUT -p tcp --dport 61000 -j DROP
Then, to scan the entire IPv4 space, the following command is used:
1
$ sudo masscan 0.0.0.0/0 --source-port 61000 -p443,8443,4443,8080,993,587,465,2525,5269,1194 --rate 400000 -oL ssl.masscan --excludefile exclude.conf
Options:
- –source-port
- This should be the port you firewalled.
- -p
- Ports to probe
| Protocol | Ports |
|---|---|
| HTTPS | 443, 8443, 4443, 8080 |
| IMAP | 993 |
| SMTP | 587, 465, 2525 |
| XMPP* | 5269 |
| OpenVPN* | 1194 |
- –rate
- Packets Per Second. We’re able to reach a speed of around 400 kpps on a
c5n.largeinstance. - -oL
- Output results to a file, in the ‘list’ format.
- –excludefile
- File containing hosts to skip. Masscan ships with a file for this purpose, excluding governments, military contractors and the like. Probably a good idea.
* I did not include these ports in my initial scan, but plan on doing so in the future
Note: This will take a long time! If you’re like me, you should probably set a reminder. Don’t forget to terminate your instances when you’re done, or Jeff Bezos will eat your bank account. I found out the hard way!
My scan finished in about 30-35 hours (tmux is your friend), having scanned a total of 3,727,369,725 hosts discovered 90,012,918 live host/port pairs and saved ~10 GB worth of results.
Scraping Certs 😎
Scouring the internet for the right tool for the job, I came across Cero, which is FOSS and pretty much perfect for my use-case.
You feed it a list of hosts/ports, it then connects to every host, scraping domains and subdomains from the SSL certs if it finds any, and does so extremely fast, easily running with the maximum conncurrency set to 50000.
I parsed the masscan output into a format that cero would understand (ip:port) using sed like so:
1
$ pv ssl.masscan | sed 's/^open tcp \([0-9]*\) \([0-9.]*\).*$/\2:\1/g' > cero_input.txt
(substitute pv for cat if you don’t have pv installed on your system, but I highly recommend it, as it pops a progress bar for you!)
… and piped this new list of parsed hosts to cero:
1
$ cat cero_input.txt | cero -d -t 2 -c 50000 > domains.txt
Options:
- -d
- Output only valid domain names (e.g. strip IPs, wildcard domains and gibberish)
- -t
- TLS Connection timeout in seconds
- -c
- Concurrency level
This will take a long time too!
Wordlist Mangling Process 🛠
Waking up the next day, having let cero run in a tmux session all night, I was left with a 844.9 MB list of a mixture of domains and subdomains, which obviously needed some cleanup.
1):
I wrote a quick Python script, using the tldextract module to get rid of domains without subdomains, remove TLDs and SLDs, flatten multi-level subdomains, convert everything to lowercase and write it to a new file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import re
import tldextract
from tqdm import tqdm
print("Loading file...")
with open("domains.txt", "r") as infile:
domains = infile.read().splitlines()
with open("subs.txt", "a+") as outfile:
for domain in (pbar := tqdm(domains, leave=False)):
subdomain = tldextract.extract(domain).subdomain
if subdomain: # We don't want anything without subs
# Write out the full domain path
outfile.write(f"{subdomain.lower()}\n")
# Write out each subdomain level individually
for sub in subdomain.split("."):
if sub:
outfile.write(f"{sub.lower()}\n")
print("Done.")
2):
1
cat subs.txt | awk '{c[$1]++} END {for (i in c){print c[i],i}}' | pv | sort -r -n | sed 's/^[0-9]* //' > subs_sorted.txt
The above chain of commands does the following:
- Reads the list of domains (
cat) - Prepends a number representing the total amount of identical lines to each line (for sorting) and removes any duplicates (
awk) - Shows the overall progress (
pv) - Sorts the list numerically, descending, so the domains will be sorted by frequency of occurrence in the dataset. This way the subdomains with the highest probability of existing on a given domain, will be tested first when using the resulting wordlist (
sort) - Removes the numbers prepended by
awkfrom each line (sed) - Writes the result to a file (
> subs_sorted.txt)
We are then left with 4,552,329 lines, or ~97 MB.
Let’s check out the top 20:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
$ head -n 20 subs_sorted.txt
www
m
mail
kubernetes
kubernetes.default
kubernetes.default.svc.cluster
api
cdn
autodiscover
secure
webmail
fritz
www.fritz
cpanel
webdisk
media
images
static
dev
stage
Yeah, that seems about right!
3):
Now, on the other hand, the bottom of the wordlist has some pretty obscure and specific entries like these:
1
2
3
4
5
1fd8c394310b1fb11b13a2a399bb2feb.sk1.us-west-1.eks
00-0279-3bab-013e-00
0-www.pressreader.com.wam
ef24f0e14110ca5eaf88f67ccdfed009.traefik (so many of these!)
00fatburn31ket1xn
These aren’t of any value to us, so naturally I utilized the scientifically well-established technique, of scrolling up from the bottom until it stopped looking too weird, deciding that’s where it ends and rounded to a length of 3,000,000 lines, making the total size ~49 MB.
Benchmarking 💪
It would be interesting to see how this new wordlist performs compared to the well-known lists floating around the internet, which I have used quite a lot myself.
Trying to come up with a meaningful benchmarking method, I’ve settled on the following process:
- Get list of Top 1 Million domains from Alexa
- Extract subset of the top 1,000
- Shuffle subset
- Extract 50 domains from subset as test sample
- Run enumeration with every chosen wordlist on all sample domains (cut own wordlist to match size of competitor), using this large list of crowd-sourced public resolvers.
- Compare number of results
I have decided on these 4 wordlists to compare against as those are the ones I’ve mainly used myself, and experienced many people using:
- 2m-subdomains.txt (Assetnote)
- all.txt (jhaddix)
- raft-large-words-lowercase.txt (RAFT)
- shubs-subdomains.txt (Shubs)
I will be using puredns for benchmarking, as I’ve found it to have the best balance of stability, speed and wildcard detection during testing using this specific method.
I have written the following shell script to streamline the process:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#!/usr/bin/env bash
# Get Alexa Top 1 Million if not present
if [ ! -f "top-1m.csv" ]; then
wget http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
unzip top-1m.csv.zip
rm top-1m.csv.zip
fi
# Define benchmarking conditions
subset_size=1000
sample_size=50
resolvers_file="resolvers-community.txt"
domains=$(head -n $subset_size top-1m.csv | shuf | head -n $sample_size | cut -d "," -f2)
wordlists=$(ls test_wordlists)
wordlist_count=$(echo -n "$wordlists" | grep -c '^')
let total=$wordlist_count*$sample_size
# Save list of domains
echo "Enumerating the following $sample_size domains:"
echo $domains | tee benchmark_domains.txt
echo "-----------------------------------------------------------"
# Cut n0kovo wordlist to size of competing wordlists
for wordlist in $wordlists; do
listsize=$(wc -l <$wordlist)
head -n $listsize n0kovo_subdomains_huge.txt >n0kovo-cut-$wordlist
done
# Run `puredns` for all domains and wordlists
# saving the results for further analysis
count=1
for domain in $domains; do
for wordlist in $wordlists; do
echo "Testing $domain using $wordlist ($count/$total)"
puredns bruteforce $worddlist $domain --resolvers $resolvers_file -t 1000 >>./found/$wordlists.found
puredns bruteforce n0kovo-cut-$wordlist $domain --resolvers $resoslvers_file -t 1000 >>./found/n0kovo-$wordlist.found
((count++))
done
done
# Write statistics
for file in ./found/*.found; do
echo $(wc -l $file) | tee -a statistics.txt
done
Comparison 📊
After letting the above process run for several days, the results are in. So, did I make an overall better wordlist? In some ways!
Cut to size:
Here’s a bar chart visualization of the results:
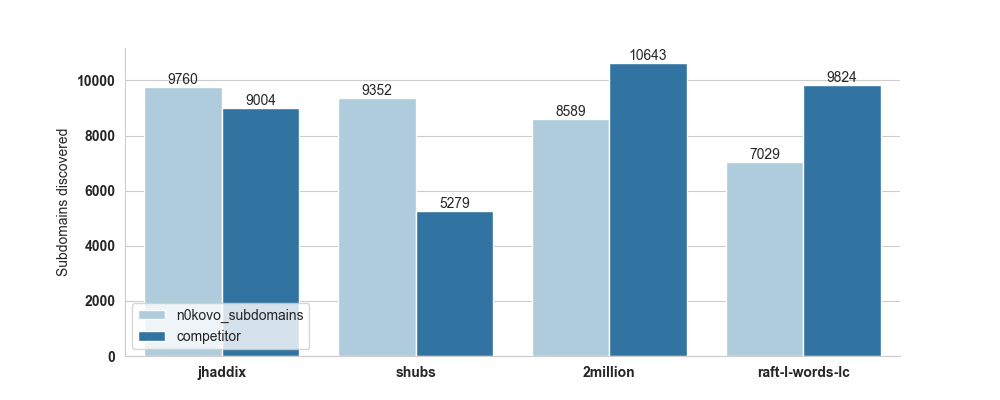 (made with Seaborn)
(made with Seaborn)
Having cut my wordlist to match the size of each competing list, the list is obviously not weilding it’s true power, but in terms of size vs. results, it seems to be performing quite well.
Full wordlist:
Let’s try and compare using the the full wordlist. In the meantime, I came across another subdomain wordlist called best-dns-wordlist.txt, made by the fine folks over at Assetnote, who also did 2m-subdomains.txt, so I’m going to include that one in this test as well. It has 9,544,235 lines, so it’s over 3 times larger than mine! But again, what we’re going for is a good balance between size and hits.
This time we’re going with just 5 pseudo-randomly chosen domains from Alexa’s top 1000, as at this point, spending any more money on EC2 would be financially irresponsible of me.
Here are the results: 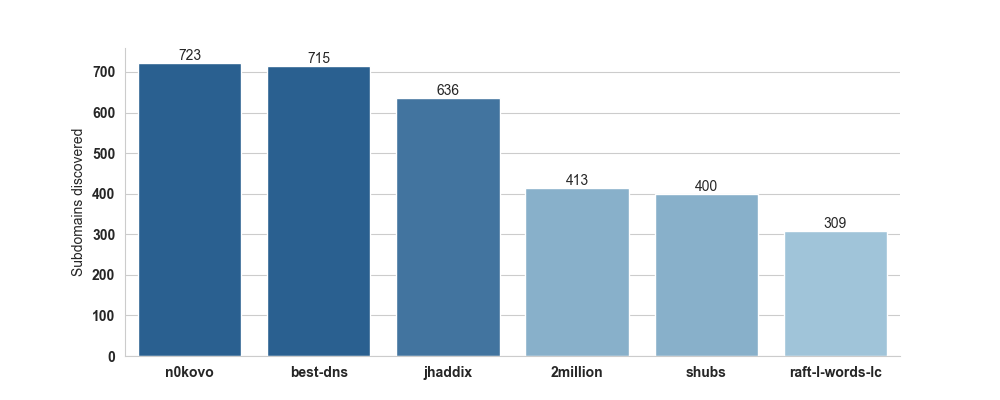 I’m feeling pretty good about this!
I’m feeling pretty good about this!
As you can see, our wordlist actually outperforms best-dns-wordlist.txt by a bit! And considering that ours is a third of the size, I would say that’s a pretty clear win! (Though, again, keep in mind that we only tested on 5 domains.)
Let’s compare size to number of hits:
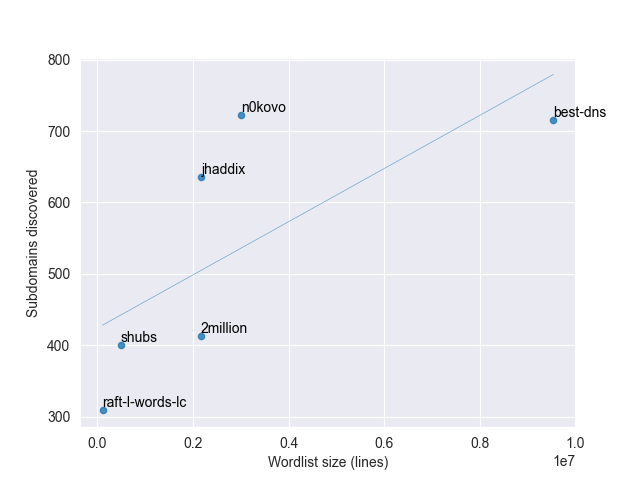 On this scatter plot, it becomes quite clear just how absolutely humongous
On this scatter plot, it becomes quite clear just how absolutely humongous
the best-dns wordlist actually is, compared to how many hits it gave us.
Conclusion ✅
So what can we learn from this?
All in all this was a pretty fun and educational exercise.
The resulting wordlist seems to fill out a gap between jhaddix’s all.txt and Assetnote’s best-dns-wordlist.txt. Sometimes it makes sense to plow through >9,000,000 DNS requests. Other times it doesn’t. Sometimes speed is essential. There are many factors. I guess there’s a time and place for every wordlist 🤔
I’ve put the list on GitHub for anyone to download.
Also, this is the first write-up of this kind I’ve ever written, so if you enjoyed it (or didn’t), please don’t hesitate to reach out to me on Mastodon and tell me!
Stay tuned for part 2 where I plan on making a bunch of TLD-specific wordlists and trying them out in the wild.